The ABC’s of Federated Learning
The stale use of buzzwords can lead to the disregard of potentially significant technology. For example, the prominent use of virtual reality has been solely in the gaming industry. Only recently has this technology received attention in the healthcare and therapy space, due to its ability to increase empathy in patients. Categorized by Gartner as ‘On the Rise’ technology for data science in 2019, federated learning may follow the similar trend of initial disregard. In the next five minutes, we will learn about the history, purpose, and applications of Federated Learning and determine if this technology may be more than just another buzzword.
Origins
The term Federated Learning was coined by Google in 2016 in a paper that aimed to solve the problem of training a centralized machine learning model given the data is distributed among millions of clients (in this case, mobile phones). The ‘brute-force’ method of solving this is to have the clients (your phone) send all the data to Google to be processed. There are many problems with this approach, such as high client data usage and lack of data privacy. The solution proposed by the paper was to send a local model to each device, compute the global minimum (the optimal parameters) for that client, and send the computed weights to the centralized, or federated, server. The central node will iterate through the parameters of all clients and average (or any other aggregation method) the optimal parameters for a global model.
As a result, only two exchanges of small files (model and weights) occur and yet, we are still able to calculate the optimal model for the clients. This is not only applicable to companies operating at Google’s scale, but also for decentralized computing purposes.
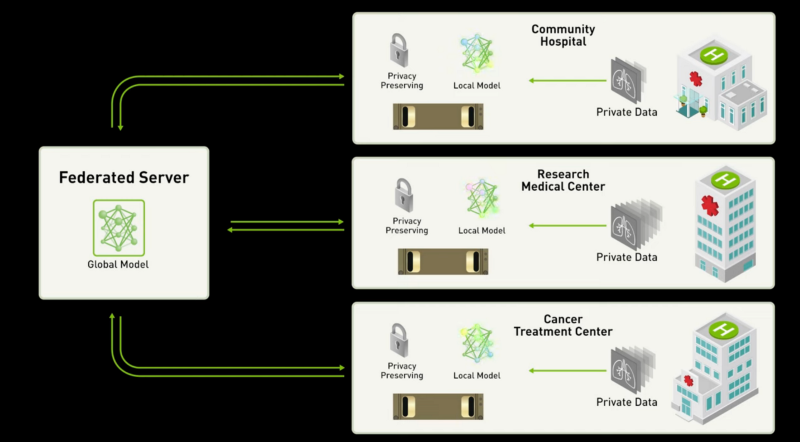
Applications
NVIDIA Clara
A requirement for efficient AI is lots of data. Otherwise, the model has most likely overfitted the small data set and will result in lower accuracy with new data points. This is especially true in regards to models in the health care sector. The small percentage chance of cancer itself results in small datasets for hospitals. This is furthered as different hospital centers are not willing to union the datasets due to privacy and legal reasons. As a result, the ability to develop state of the art models for healthcare diminishes.
NVIDIA is aiming to change that with their Clara software library. The architecture of the image above is as follows: a region of hospitals may decide to collaborate their analytics in order to maximize the potential of their data set. The hospitals will develop a centralized server to perform all the computation, and all the hospitals will simply send their local weights to the server. The server will develop the optimal generalized model and distribute the global model to all parties. No party will interface with the data, but after global computation, each client will receive only the result of the optimal model. It is important to note that federated learning can easily be identifiable, as each model can be tagged with the user ID. NVIDIA acknowledges this fact and developed the Clara framework to combat the ability to access information within the centralized server.
VIA & the Trusted Analytics Chain
The original paper proposed by Google utilized federated learning to improve keyboard predictions for Gboard (Google’s mobile keyboard). This allowed for Gboard to learn from all its customers to make the optimal prediction service generalizable for every user. Modern uses of federated learning have surpassed this traditional AI architecture. VIA is working on an energy blockchain platform for trading analytics and data services. Known as the Trusted Analytics Chain, the platform utilizes a blockchain network to track interactions with the global server and model. The benefit of combining these technologies is the immutability of the access logs, such that any breach of policies are recorded without failure and privacy is completely ensured.
VIA is trying to solve the problem of energy outages and theft. The chance of an energy outage is less than ~1%, which means the data set for positive cases is extremely small. Therefore, energy organizations will benefit from better analytics and insights with consolidated data, without the cost of privacy. Blockchain enables trust between parties and trust in the protection of the centralized data source. Via was recently accepted into Plug and Play’s Energy and sustainability accelerator program, a Silicon Valley venture capital firm. The architecture of Via is more complex than Clara, as analytics can be purchased and data can be staked. Therefore, the decentralization benefits are utilized to ensure staking rewards via consensus and validation.
The Distributed and Decentralized Future
Google has published a library for utilizing decentralized machine learning as an addition to their famous AI library, known as TensorFlow Federated. The combination of blockchain and federated learning seems to fulfill the current need of private distributed computing in both centralized (NVIDIA’s Clara) and decentralized communities (Via’s Trusted Analytics Chain).
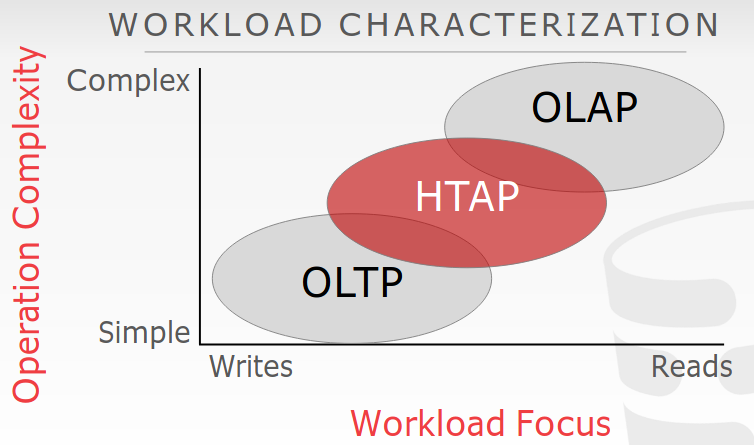
Observing the trends of data processing from the image above, we see the need for both Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) in businesses. Banks need to validate and check incoming transactions that occur every second (OLTP), but they will also need to perform machine learning and other statistical analysis on the data to improve customer experience (OLAP). Blockchain primarily supports OLTP, as it allows an application to check the status of each individual asset. On the other hand, analytical processing does not currently occur directly within the blockchain network, as blockchain is optimized for transaction throughput, not machine learning.
However, as the needs of the consumers evolve, blockchain will need to be able to support OLAP and deep insights (potentially offloaded to non-network nodes). Federated Learning is one modern method of doing so. We can ensure the trust of the access to and the data itself, as provisioned by the global distributed ledger. The possibility of both decentralized and centralized trust may help circumvent the privacy limitations of small data sets. In a blog post by Google, it was confirmed that Gboard’s federated learning model is still in production in 2019, 3 years after deployment, which is promising. The provision of private and smart services enable the potential for a hybrid data-sharing economy to improve analytics for all parties, with no cost of privacy. LightWorks is currently in progress of developing a data commons model with private distributed AI models for the carbon warehouse. The benefits of this approach allows parties who do not want to share data to be able to reap the benefits of a large data set.